Why I like ARC-AGI
A week ago, ARC-AGI-3 came out. A third benchmark in a series trying to measure the gap between what AI models can do and what humans can do. The basic idea is to find tasks that are easy for humans but hard for AI. I think it is one of the most interesting benchmarks in recent years for model progression, both because of what it measures and how it measures it.
In previous episodes: ARC-AGI-1 came out in 2019 (!) and only recently have models been able to approach human-level success rates (humans: 98%; best model as of today, Gemini 3 Deep Think, with 96%). ARC-AGI-2 came out a year ago, but the gap was closed much more quickly (humans: 100%; Gemini 3 Deep Think with 84.6%).
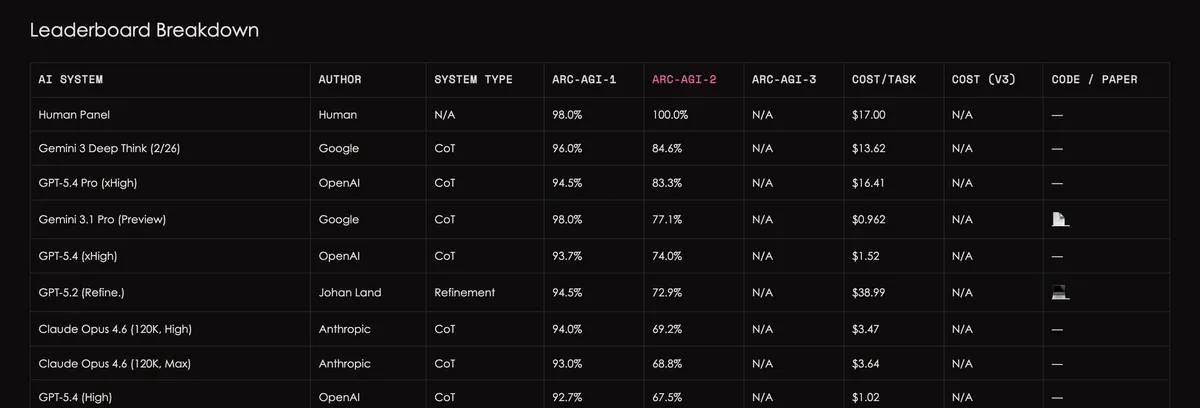
What makes this special compared to other benchmarks? First, the type of problems: we all know how good models are at writing code, but there are still tasks where they fail miserably and make mistakes humans would never make. ARC-AGI tries to quantify this gap—tasks humans “just get” how to solve, while models still struggle. This is at least as interesting as measuring how well they write code, and arguably even more so.
Its uniqueness also comes from how the benchmark is constructed. Each benchmark in the series has two sets of problems—a public set and a private set, exposed only to the benchmark creators (technically, there is also a semi-private set, but it doesn’t add much here). In a world where it is easy to overfit to a specific benchmark (intentionally or by mistake), this design gives credibility that other benchmarks lack. When I see the score on the private set, I know there is no way the models saw it during training.
So what is new this time? ARC-AGI-3 tries to follow current trends and measure models on “agentic” tasks—tasks that require planning and taking actions across steps. For example: navigating a maze and pressing a button until two shapes are identical.
As with everything, ARC-AGI-3 has its critics. Some argue that these tasks are designed to make models fail on purpose (since when are we on the side of the models?). I do think there have been some non-trivial choices in designing these tasks, but overall this is a matter of framing. For example, the score this time is not determined by task success rates, but by the squared gap between the number of actions taken by the model and by a human. Why squared? Because it penalizes larger gaps more heavily and provides better granularity as models get closer to human performance. Some people complain that this drives scores down, but that misses the point: either the models succeed or they do not. Encouraging efficiency seems like a reasonable goal, and if the scoring reflects that with extra emphasis, I’m for it.

One detail I do not like: unlike ARC-AGI-1 and ARC-AGI-2, submissions this time do not allow prompts or custom systems tailored specifically to the benchmark. The creators argue (reasonably) that if we reach “Artificial General Intelligence,” there should be no need for task-specific prompting—general is general. However, they do allow anything hidden behind a model API (e.g., if OpenAI includes a specific prompt behind the GPT-5.4 API, that is acceptable). This feels like an arbitrary line to draw, but fine.
One last point worth remembering: although ARC-AGI-3 is out, ARC-AGI-2 is not yet solved. The best model still scores about 15% below humans. The focus will naturally shift to ARC-AGI-3, which is somewhat unfortunate - for these kinds of problems, the tail of difficult cases is the most interesting.